

Стандартное отклонение — классический индикатор изменчивости из описательной статистики.
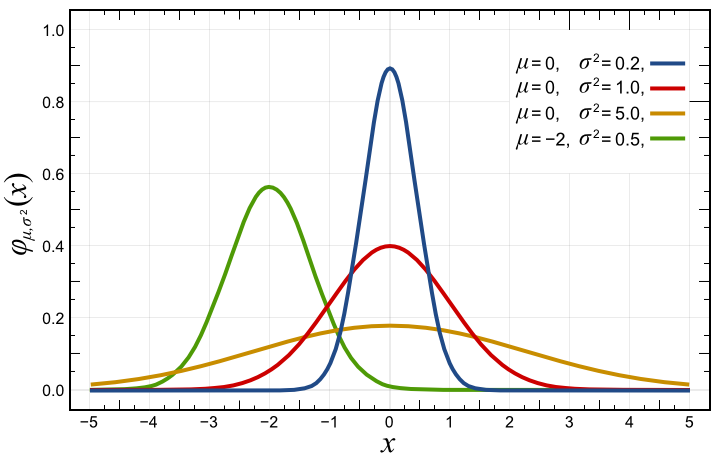
Стандартное отклонение, среднеквадратичное отклонение, СКО, выборочное стандартное отклонение (англ. standard deviation, STD, STDev) — очень распространенный показатель рассеяния в описательной статистике. Но, т.к. технический анализ сродни статистике, данный показатель можно (и нужно) использовать в техническом анализе для обнаружения степени рассеяния цены анализируемого инструмента во времени. Обозначается греческим символом Сигма “σ”.
Спасибо Карлам Гауссу и Пирсону за то, что мы имеем возможность пользоваться стандартным отклонением.
Используя стандартное отклонение в техническом анализе, мы превращаем этот “показатель рассеяния” в “индикатор волатильности“, сохраняя смысл, но меняя термины.
Что представляет собой стандартное отклонение
Понимание сути стандартного отклонения возможно с пониманием азов описательной статистики. К примеру, мы имеем 2 выборки, у которых среднее арифметическое одинаково и равно 3. Казалось бы, одинаковое среднее делает эти две выборки одинаковыми. Ан-нет! Давайте рассмотрим возможные варианты данных для этих двух выборок:
- 1, 2, 3, 4, 5
- -235, -103, 3, 100, 250
Очевидно, что разброс (или рассеяние, или, в нашем случае, волатильность) гораздо больше во второй выборке. Следовательно, несмотря на то, что у этих двух выборок одинаковое среднее (равное 3), они совершенно разные в силу того, что у второй выборки данные беспорядочно и сильно рассеяны вокруг центра, а у первой — сконцентрированы около центра и упорядочены.
Но если нам надо быстро дать понять о таком явлении, мы не будем объяснять, как в абзаце выше, а просто скажем, что у второй выборки очень большое стандартное отклонение, а у первой — очень маленькое. Так, у второй выборки стандартное отклонение равно 186, а у первой оно равно 1,6. Разница существенная.
Стандартное отклонение в техническом анализе
Стандартное отклонение используется в техническом анализе не так часто, но оно служит отличным индикатором волатильности (изменчивости). Стандартное отклонение используется для промежуточных вычислений различных индикаторов, таких как, например, Полосы Боллинджера или Ширина Полос Боллинджера.
Но помимо промежуточных вспомогательных вычислений, стандартное отклонение вполне приемлемо для самостоятельного вычисления и применения в техническом анализе. Как отметил активный читатель нашего журнала burdock, “до сих пор не пойму, почему СКО не входит в набор стандартных индикаторов отечественных диллинговых центров“.
Действительно, стандартное отклонение может классическим и “чистым” способом измерить изменчивость инструмента. Но к сожалению, этот индикатор не так распространен в анализе ценных бумаг.
Применение стандартного отклонения
Для любого индикатора нам понадобится переменная, т.е. параметр. В данном случае нам нужен только период n, который указывает, какое количество периодов мы будем включать в вычисление стандартного отклонения.
Для вычисления, мы берем данные закрытия из n периодов назад от последней доступной цены. Т.е. если мы установили период индикатора 20 (достаточно часто используемый период),то мы берем 20 последних данных и оперируем ими для вычисления стандартного отклонения сегодня. Следовательно, для вычисления стандартного отклонения в любой момент времени k, надо взять цены закрытия всех n периодов назад от k.
Вычисление стандартного отклонения
Предупреждаю, что самостоятельное вычисление вам врядли понадобиться, т.к. основные программы обработки данных имеют встроенную функцию вычисления стандартного отклонения. Например, в Microsoft Excel эта функция называется СТАНДОТКЛОН.
Вручную вычислить стандартное отклонение не очень интересно, но полезно для опыта. Стандартное отклонение можно выразить формулой STD=√[(∑(x-x)2)/n], что звучит как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
Если количество элементов в выборке превышает 30, то знаменатель дроби под корнем принимает значение n-1. Иначе используется n.
Пошагово вычисление стандартного отклонения:
- вычисляем среднее арифметическое выборки данных
- отнимаем это среднее от каждого элемента выборки
- все полученные разницы возводим в квадрат
- суммируем все полученные квадраты
- делим полученную сумму на количество элементов в выборке (или на n-1, если n>30)
- вычисляем квадратный корень из полученного частного (именуемого дисперсией)
Для наглядности, вот пример из таблицы Excel:
")
Исходный файл Excel прилагается (.xls 24kb).
В данном примере я взял краткий отрезок исторических данных цен закрытия индекса ПФТС. Для вычислений, дата не нужна, но я решил ее оставить, чтоб вы могли сверить, если хотите. Что действительно важно, это все остальное. Обратите внимание на отдельные данные под темным разделителем: “среднее” и “всего”. Есть столбец с ценой закрытия, столбец с разницами данных и среднего, и квадраты этих разниц.
После вычисления квадратов, мы складываем их, полученную сумму делим на количество элементов выборки (т.к. всего элементов 24, что меньше 30) и из полученного честного вычисляем квадратный корень. Результат округляем до целого, и получаем 69.
Важно заметить, что все эти вычисления дадут нам лишь значение индикатора «стандартное отклонение» в последний день, т.е. 26.09.2008, а для каждой другой даты надо проделывать этот комплекс операций отдельно.
Прикладное значение стандартного отклонения
Напомню, что смысл стандартного отклонения заключается в выявлении степени изменчивости инструмента. Т.е. стандартное отклонение не сможет показать аналитику ничего, кроме волатильности.
Важно отметить, что элементы выборки в среднем отличается от среднего значения на ±СО. Т.е. из примера выше, цены закрытия индекса ПФТС в среднем отличаются от среднего значения на ±69.
Из примера выше, отдельно цифра 69 ничего не скажет, т.к надо ее использовать с другими значениями стандартного отклонения в другие периоды. 69 — относительно немалая волатильность, но если в другие периоды стандартное отклонение будет больше 100, то, естественно, 69 окажется умеренной изменчивостью. Т.е. “все познается в сравнении“.
Вывод
Стандартное отклонение — классический индикатор изменчивости из описательной статистики. Он поможет увидеть, как изменяется волатильность инструмента во времени.




Я уже 4 дня по формулам в интрнете пытаюсь рассчитать СО и вообще понять ЧЕ ЭТО ТАКОЕ.
Вы себе не представляете каким счастливым вы меня сделали!
Статья очень доходчиво написана. Тут и пример есть и программа в Экселе и минимум текста, но за-то каждое слово ценно. СПАСИБО!!!!
Да!! Согласен с Читателем!Статья действительно отличная, как и все остальные на этом сайте!
Спасибо!
В разделе “Вычисление стандартного отклонения” есть такая формулировка:
“Стандартное отклонение можно выразить формулой STD=√[(∑(x-x)2)/n], что звучит как корень из суммы разниц между элементами выборки и средним, деленной на количество элементов в выборке”.
Следует читать:
“Стандартное отклонение можно выразить формулой STD=√[(∑(x-x)2)/n], что звучит как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке”.
Если оценивать материал в целом, то подан он очень добротно (доходчиво).
Вам не кажется, что тут закралась некоторая ошибка?
если для выборки 1,2,3,4,5 брать знаменатель n (=5), то среднеквадратичное отклонение будет 1.5, а не 1.6 как пишется в статье.
По другим источникам, получается наоборот – при малом количестве выборок берется n-1, при большом берется любое – либо n, либо n-1.
Более того этим и отличаются "стандартное отклонение" (n-1) от "среднеквадратичного" (n)
Друзья,спасибо Вам огромное,ВЫ оч оч оч оч оч помогли,я как начинающий пытался долго понять,что это такое и зачем нужно,но в учебниках все одна вода,спасибо за ясность,которую вы внесли в подобного рода коллапс=)
Респект=)
Статья понравилась, иногда даже слишком подробная.
Но вкралась ошибочка:
“Важно отметить, что элементы выборки в среднем отличается от среднего значения на ±СО”
Элементы выборки отличаются в среднем на sum(abs(отклонений от среднего))/n (В excel – СРОТКЛ()), а Стандартное отклонение, как показал мой скромный опыт (могу ошибаться) – более отзывчивый к изменчивости/волатильности индикатор.
n берется если вы вычисляете СКО для генеральной совокупности, если вы имеете дело с выборкой, то берется n-1. А СКО и СО ничем, кроме названия друг от друга не отличаются..
Надо отдать должное автору, статья замечательная, лучшая из всех, с которыми мне приходилось знакомиться, понятная даже школьникам. После таких статей начитаешь любить математику и статистику. На мой взгляд, статья будет полнее, если привести простые и яркие примерами, где это можно применить.
Согласен с Сомневающимся в части 1,5 а не 1,6. Если отбросить данные извне формулы СО и дисперсии, а рассуждать с точки зрения простой логики. Тогда среднее отклонение от среднеарифметического вычисляется как среднеарифметическое модулей разностей отклонений от среднеарифметического, т.е. (мод(3-2)+мод(3-1)+мод(3-4)+ мод(3-5))/4 = 1,5. Что и понятно логически – лежит ровно посередине между 4 и 5 или 1 и 2. И в этом есть геометрический смысл. А по формулам выходит 1,6. Понять не могу. Может, кто-нить просветит?
Отличная статья. Спасибо автору.
А что касается n, то, похоже, действительно неточность. Т.к. при больших n вычитание единицы будет оказывать весьма незначительное воздействие на результат и им можно пренебречь. Т.о. при малых n следует использовать n-1, а при больших – единицу можно не вычитать.
Это просто потрясающая статья!!!! Я по-моему весь интернет перелопатила, чтобы хоть что-нибудь понять!!!
Огромное спасибо автору!!!
Было бы по больше нормальных, коротких и понятных статей)))
спасибо Вам, Человек. огромный респектище, даже мне-имбецилу стало понятно. и пох, что мой коммент Вам не всрался, пардон за мой французский
….присоединяюсь к благодарностям, только что очень выручил. Только с этого сайта скатала объяснения нормальные.
Статья прекрасная! Долго не могла найти такого доходчивого и понятного описания. То, что нужно! Спасибо большое автору!
Нормально! Я все поняла!
Спасибо.
Очень доходчивая статья, прочитал на одном дыхании) Все просто и ясно изложена, согласен с Игорем, после прочтения статьи начинаешь больше интересоваться статистикой. Добавляю сайт в закладки. Спасибо!
Мне не совсем понятно утверждение: “элементы выборки в среднем отличается от среднего значения на ±СО.” Насколько я помню, значение искомой величины есть [x]± t*CO/(корень из n), где t-коэф.Стьюдента, n – количество элементов.
например применяется в xyz анализе, для определения классов товаров и для определения по ним страхового запаса ввиде прибавления СКО к среднему значению в условиях неопределенности
спасибо, очень доступное раскрытие сложного математического термина, если это возможно – посмотрите на стандартное отклонение в программе Wealth-Lab Developer 3.01. Написал алгоритм, хочу заавтоматить, но не могу нормальное ТЗ для программиста составить, споткнулся на формуле STDDEV, заранее благодарен.
По приведенной формуле нерационально рассчитывать СО, поскольку она требует два прохода (расчет среднего и дисперсии)формулу можно изменить и считать за один проход (сумму и сумму квадратов). Формулу не привожу, боюсь налажал с n. Надо в Нете поискать.
Отличная статья, но осталось непонятным, как рассчитывается канал Стандарное отклонение в терминале Метатрейдер 4
Спасибо автору статьи. Дело в том что я преподаю Excel для продвинутых пользователей и как раз собирался дат лекцию по стандартному отклонению. Так как моя специальность не статистик нуждался в таком доходчивом объяснении для для таких чайников как я. Отзыв оставляю для того чтобы автор продолжал писать такие статьи.
Привет из Баку!
С уважаем – Самир
Глубокоуважаемый автор, спасибо за замечательную статью, но, может быть я ошибаюсь, но в вашем алгоритме пошагового вычисления закралась ошибка.
Пошагово вычисление стандартного отклонения сначала нужно суммировать значения, затем возводить в квадрат, т.к. квадрат даже отрицательного числа будет положительным. В этом случае дисперсное значение будет неверным. Жду ответа.